mdbookkit

Quality-of-life plugins for your mdBook project.
-
rustdoc-style linking for Rust APIs: write types and function names, get links to docs.rs
-
Permalinks for your source tree: write relative paths, get links to GitHub.
Installation
If you are interested in any of these plugins, visit their respective pages for usage instructions, linked above.
If you want to install all of them:
cargo install mdbookkit --all-features
Precompiled binaries are also available from GitHub releases.
License
This project is released under the Apache 2.0 License and the MIT License.
mdbook-rustdoc-link
For best results, view this page at https://tonywu6.github.io/mdbookkit/rustdoc-link.
rustdoc-style linking for mdBook (with the help of rust-analyzer).
You write:
The [`option`][std::option] and [`result`][std::result] modules define optional and
error-handling types, [`Option<T>`] and [`Result<T, E>`]. The [`iter`][std::iter] module
defines Rust's iterator trait, [`Iterator`], which works with the `for` loop to access
collections. [^1]
You get:
The option and result modules define optional and
error-handling types, Option<T> and Result<T, E>. The iter module
defines Rust's iterator trait, Iterator, which works with the for loop to access
collections. 1
mdbook-rustdoc-link is an mdBook preprocessor. Using rust-analyzer, it converts type
names, module paths, and so on, into links to online crate docs. No more finding and
pasting URLs by hand.
Overview
To get started, simply follow the quickstart guide!
If you would like to read more about this crate:
For writing documentation —
- To learn more about how it is resolving items into links, including feature-gated items, see Name resolution.
- To know how to link to other types of items like functions, macros, and implementors, see Supported syntax.
For adapting this crate to your project —
- If you use Cargo workspaces, see specific instructions in Workspace layout.
- If you are working on a large project, and processing is taking a long time, see the discussion in Caching.
For additional usage information —
- You can use this as a standalone command line tool: see Standalone usage.
- For tips on using this in CI, see Continuous integration.
- For all available options and how to set them, see Configuration.
- Finally, review Known issues and limitations.
Happy linking!
License
This project is released under the Apache 2.0 License and the MIT License.
-
Text adapted from A Tour of The Rust Standard Library ↩
Getting started
Follow these steps to start using mdbook-rustdoc-link in your book project!
Install
You will need to:
-
Have rust-analyzer:
- If you already use the VS Code extension: this crate automatically uses the server binary that comes with it, no extra setup is needed!
- Otherwise, install rust-analyzer (e.g. via
rustup) and make sure it's on yourPATH.
-
Install this crate:
cargo install mdbookkit --features rustdoc-linkOr you can grab precompiled binaries from GitHub releases.
Configure
Configure your book.toml to use it as a preprocessor:
[book]
title = "My Book"
[preprocessor.rustdoc-link]
# mdBook will run `mdbook-rustdoc-link`
after = ["links"]
# recommended, so that it can see content from {{#include}} as well
Write
In your documentation, when you want to link to a Rust item, such as a type, a function, etc., simply use its name in place of a URL, like this:
Like [`std::thread::spawn`], [`tokio::task::spawn`] returns a
[`JoinHandle`][tokio::task::JoinHandle] struct.
The preprocessor will then turn them into hyperlinks:
Like std::thread::spawn, tokio::task::spawn returns a
JoinHandle struct.
This works in both mdbook build and mdbook serve!
To read more about this project, feel free to return to Overview.
important
It is assumed that you are running mdbook within a Cargo project.
If you are working on a crate, and your book directory is within your source tree,
such as next to Cargo.toml, then running mdbook from there will "just work".
If your book doesn't belong to a Cargo project, refer to Workspace layout for more information on how you can setup up the preprocessor.
tip
mdbook-rustdoc-link makes use of rust-analyzer's "Open Docs" feature,
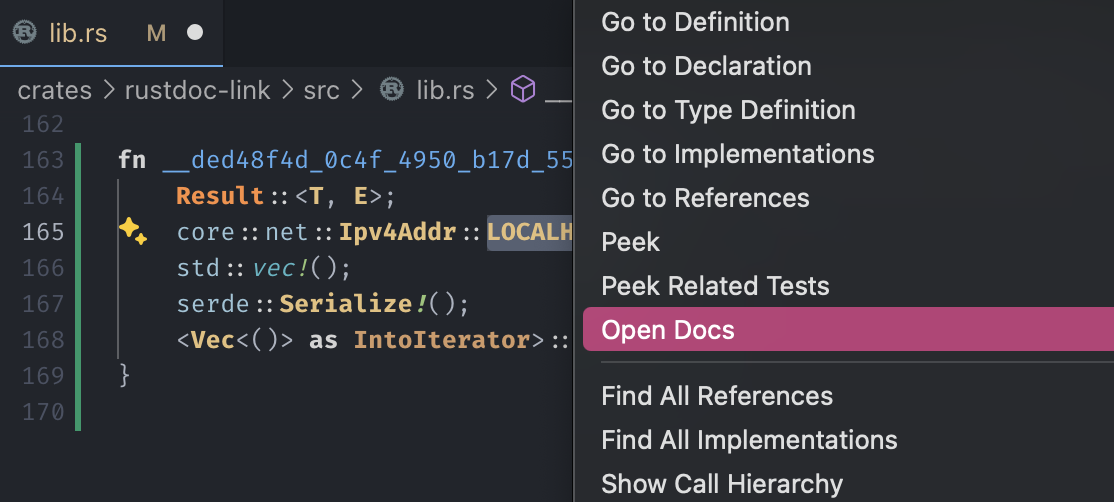
which resolves links to documentation given a symbol.
Items from std will generate links to https://doc.rust-lang.org, while items from
third-party crates will generate links to https://docs.rs.
So really, rust-analyzer is doing the heavy-lifting here. This crate is just the glue code :)
Motivation
rustdoc supports linking to items by name, a.k.a. intra-doc links. This is awesome for at least two reasons:
- It's convenient. It could be as simple as just adding brackets.
- Docs.rs will generate cross-crate links that are version-pinned.
mdBook doesn't have the luxury of accessing compiler internals yet, so you are left with manually sourcing links from docs.rs. Then one of two things could happen:
-
APIs are mentioned without linking to reference docs.
This is probably fine for tutorials and examples, but it does mean readers of your docs won't be able to move from guides to references as easily.
-
You do want at least some cross-references, but it is cumbersome to find and copy the correct links, and even more so to maintain them.
Links to docs.rs often use
latestas the version, which could become out-of-sync with your code, especially if they point to third-party or unstable APIs.
mdbook-rustdoc-link is the tooling answer to these problems. Effortless, correct, and
good practice — choose all three!
note
That being said, sometimes manually specifying URLs is the best option.
Most importantly, writing links by name means they won't be rendered as such when your Markdown source is displayed elsewhere. If your document is also intended for places like GitHub or crates.io, then you should probably not use this preprocessor.
Name resolution
mdbook-rustdoc-link resolves items in the context of your crate's "entrypoint", which
is usually your lib.rs or main.rs (the specific rules are
mentioned below).
tip
If you use Cargo workspaces, or if your source tree has special layout, see Workspace layout for more information.
An item must be in scope in the entrypoint for the proprocessor to generate a link for it.
Let's say you have the following as your lib.rs:
use anyhow::Context;
/// Type that can provide links.
pub trait Resolver {}
mod env {
/// Options for the preprocessor.
pub struct Config {}
}
Items in the entrypoint can be linked to with just their names:
[`Resolver`] — Type that can provide links. This crate also uses the [`Context`] trait from [`anyhow`].
Resolver— Type that can provide links.
This includes items from the prelude (unless you are using #![no_implicit_prelude]):
[`FromIterator`] is in the prelude starting from Rust 2021.
FromIteratoris in the prelude starting from Rust 2021.
Though technically not required — to make items from your crate more distinguishable
from others in your Markdown source, you can write crate::*:
[Configurations](configuration.md) for the preprocessor is defined in the [`Config`][crate::env::Config] type.Configurations for the preprocessor is defined in the
Configtype.
For everything else, provide its full path, as if you were writing a use declaration:
[`JoinSet`][tokio::task::JoinSet] is analogous to `asyncio.as_completed`.
JoinSetis analogous toasyncio.as_completed.
tip
In short, write links the way you use an item in your lib.rs or main.rs.
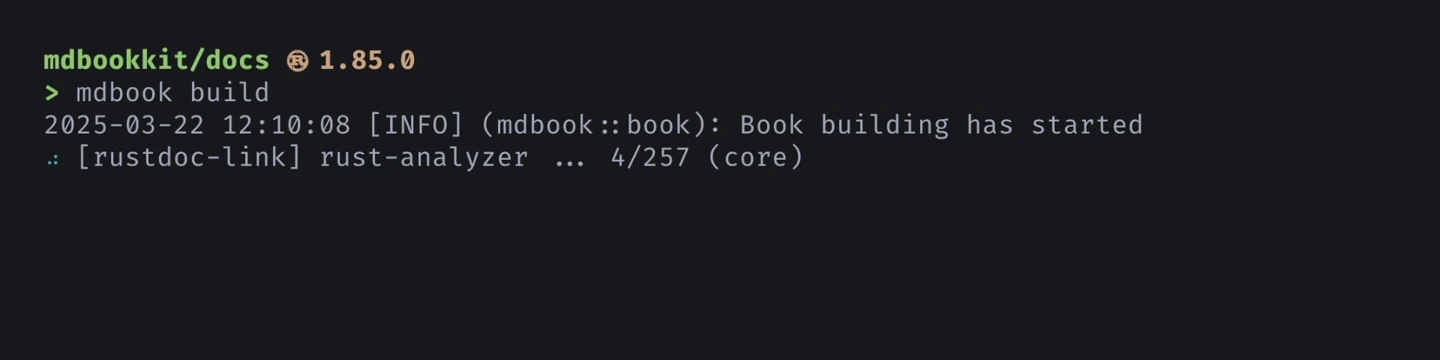
The preprocessor will emit a warning if an item cannot be resolved:
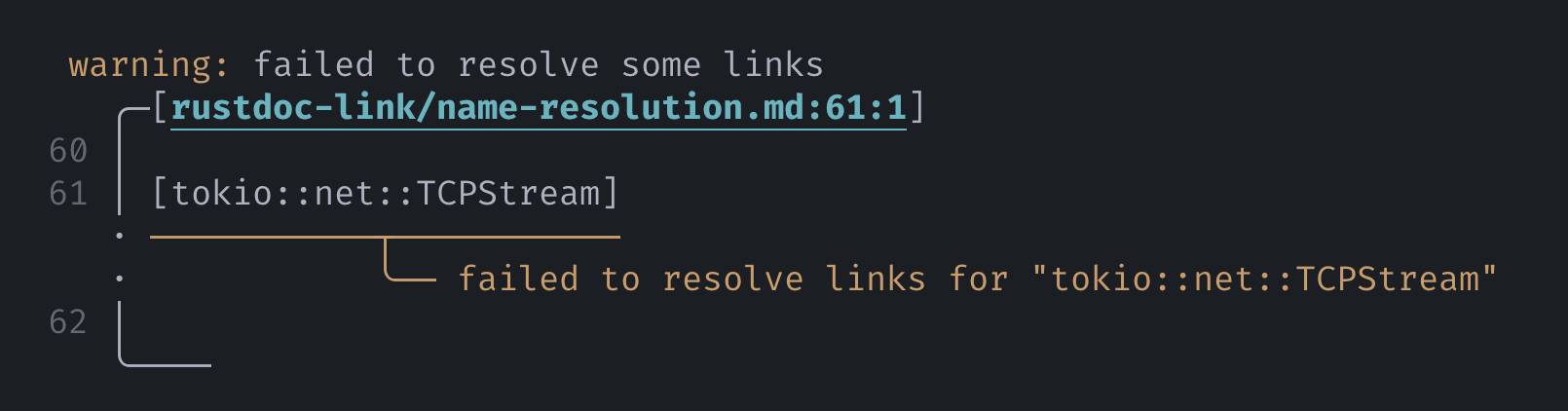
Formatting of diagnostics powered by miette
This is something to remember especially if you are including doc comments as part of your Markdown docs. Only rustdoc has the ability to resolve names from where the comments are written, so links that work in doc comments may not work when using this preprocessor!
Feature-gated items
To link to items that are gated behind features, use the
cargo-features option in book.toml.
For example, clap is known for providing guide-level documentation through docs.rs.
The tutorial for its Derive API is gated behind the unstable-doc feature. To link to
such items, configure the necessary features:
[preprocessor.rustdoc-link]
cargo-features = ["clap/unstable-doc"]
Then, specify the item as normal:
[Tutorial for clap's Derive API][clap::_derive::_tutorial]
Which entrypoint
For this preprocessor, the "entrypoint" is usually src/lib.rs or src/main.rs.
- If your crate has multiple
bintargets, it will use the first one listed in yourCargo.toml. - If your crate has both
libandbins, it will preferlib. - If your crate has custom paths in
Cargo.tomlinstead of the defaultsrc/lib.rsorsrc/main.rs, it will honor that.
How it works
note
The following are implementation details. See rustdoc_link/mod.rs.
mdbook-rustdoc-link parses your book and collects every link that looks like a Rust
item. Then it synthesizes a Rust function that spells out all the items, which looks
roughly like this:
fn __ded48f4d_0c4f_4950_b17d_55fd3b2a0c86__ () {
Result::<T, E>;
core::net::Ipv4Addr::LOCALHOST;
std::vec!();
serde::Serialize!();
<Vec<()> as IntoIterator>::into_iter;
// ...
}
Note that this is barely valid Rust —
Result::<T, E>;is a type without a value, and you wouldn't useserde::Serializeas a regular macro.This is where language servers like rust-analyzer excel — they can provide maximally useful information out of badly-shaped code.
The preprocessor appends this fake function to your lib.rs or main.rs (in memory, it
doesn't modify your file) and sends it to rust-analyzer. Then, for each item
that needs to be resolved, the preprocessor sends an external documentation
request.
{
"jsonrpc": "2.0",
"method": "experimental/externalDocs",
"params": {
"textDocument": { "uri": "file:///src/lib.rs" },
"position": { "line": 6, "character": 17 }
}
}
Hence item names in your book must be resolvable from your crate entrypoint!
This process is as if you had typed a name into your source file and used the "Open Docs" feature — except it's fully automated.
Supported syntax
For best results, view this page at https://tonywu6.github.io/mdbookkit/rustdoc-link/supported-syntax.
This page showcases all the syntax supported by mdbook-rustdoc-link.
Most of the formats supported by rustdoc are supported. Unsupported syntax and differences in behavior are emphasized below.
In general, specifying items as you would when writing Rust code should "just work".
Sections
tip
This page is also used for snapshot testing! To see how all the links would look like in Markdown after they have been processed, see supported-syntax.snap and supported-syntax.stderr.snap.
Types, modules, and associated items
Module [`alloc`][std::alloc] — Memory allocation APIs.Module
alloc— Memory allocation APIs.Every [`Option`] is either [`Some`][Option::Some][^1] and contains a value, or [`None`][Option::None][^1], and does not.Every
Optionis eitherSome1 and contains a value, orNone1, and does not.[`Ipv4Addr::LOCALHOST`][core::net::Ipv4Addr::LOCALHOST] — An IPv4 address with the address pointing to localhost: `127.0.0.1`.
Ipv4Addr::LOCALHOST— An IPv4 address with the address pointing to localhost:127.0.0.1.
Generic parameters
Types can contain generic parameters. This is compatible with rustdoc.
[`Vec<T>`] — A heap-allocated _vector_ that is resizable at runtime.
Vec<T>— A heap-allocated vector that is resizable at runtime.| Phantom type | variance of `T` | | :------------------------------------------------- | :---------------- | | [`&'a mut T`][std::marker::PhantomData<&'a mut T>] | **in**variant | | [`fn(T)`][std::marker::PhantomData<fn(T)>] | **contra**variant |
This includes if you use turbofish:
`collect()` is one of the few times you’ll see the syntax affectionately known as the "turbofish", for example: [`Iterator::collect::<Vec<i32>>()`].
collect()is one of the few times you’ll see the syntax affectionately known as the "turbofish", for example:Iterator::collect::<Vec<i32>>().
Functions and macros
To indicate that an item is a function, add () after the function name. To indicate
that an item is a macro, add ! after the macro name, optionally followed by (),
[], or {}. This is compatible with rustdoc.
Note that there cannot be arguments within (), [], or {}.
[`vec!`][std::vec!][^2] is different from [`vec`][std::vec], and don't accidentally use [`format()`][std::fmt::format()] in place of [`format!()`][std::format!()][^2]!
vec!2 is different fromvec, and don't accidentally useformat()in place offormat!()2!
The macro syntax works for attribute and derive macros as well (even though this is not how they are invoked).
There is a [derive macro][serde::Serialize!] to generate implementations of the [`Serialize`][serde::Serialize] trait.There is a derive macro to generate implementations of the
Serializetrait.
Implementors and fully qualified syntax
Trait implementors may supply additional documentation about their implementations. To
link to implemented items instead of the traits themselves, use fully qualified paths,
including <... as Trait> if necessary. This is a new feature that rustdoc does not
currently support.
[`Result<T, E>`] implements [`IntoIterator`]; its [**`into_iter()`**][Result::<(), ()>::into_iter] returns an iterator that yields one value if the result is [`Result::Ok`], otherwise none. [`Vec<T>`] also implements [`IntoIterator`]; a vector cannot be used after you call [**`into_iter()`**][<Vec<()> as IntoIterator>::into_iter].
Result<T, E>implementsIntoIterator; itsinto_iter()returns an iterator that yields one value if the result isResult::Ok, otherwise none.
Vec<T>also implementsIntoIterator; a vector cannot be used after you callinto_iter().
note
If your type has generic parameters, you must supply concrete types for them for
rust-analyzer to be able to locate an implementation. That is, Result<T, E> won't
work, but Result<(), ()> will (unless there happen to be types T and E literally
in scope).
Disambiguators
rustdoc's disambiguator syntax prefix@name is accepted but
ignored:
[`std::vec`], [`mod@std::vec`], and [`macro@std::vec`] all link to the `vec` _module_.
std::vec,mod@std::vec, andmacro@std::vecall link to thevecmodule.
This is largely okay because currently, duplicate names in Rust are allowed only if they correspond to items in different namespaces, for example, between macros and modules, and between struct fields and methods — this is mostly covered by the function and macro syntax, described above.
If you encounter items that must be disambiguated using rustdoc's disambiguator syntax, other than the "special types" listed below, please file an issue!
Special types
warning
There is no support on types whose syntax is not a path; they are currently not parsed at all:
references
&T, slices[T], arrays[T; N], tuples(T1, T2), pointers like*const T, trait objects likedyn Any, and the never type!
Note that such types can still be used as generic params, just not as standalone types.
Struct fields
warning
Linking to struct fields is not supported yet. This is incompatible with rustdoc.
Markdown link syntax
All Markdown link formats supported by rustdoc are supported:
Linking with URL inlined:
[The Option type](std::option::Option)
Linking with reusable references:
[The Option type][option-type] [option-type]: std::option::Option
Reference-style links [text][id] without a corresponding [id]: name part will be
treated the same as inline-style links [text](id):
[The Option type][std::option::Option]
Shortcuts are supported, and can contain inline markups:
You can create a [`Vec`] with [**`Vec::new`**], or by using the [_`vec!`_][^2] macro.You can create a
VecwithVec::new, or by using thevec!2 macro.
(The items must still be resolvable; in this case Vec and vec! come from the
prelude.)
Linking to page sections
To link to a known section on a page, use a URL fragment, just like a normal link. This is compatible with rustdoc.
[When Should You Use Which Collection?][std::collections#when-should-you-use-which-collection]
-
rust-analyzer's ability to generate links for enum variants like
Option::Somewas improved only somewhat recently: before #19246, links for variants and associated items may only point to the types themselves. If linking to such items doesn't seem to work for you, be sure to upgrade to a newer rust-analyzer first! ↩ ↩2 -
As of rust-analyzer
2025-03-17, links generated for macros don't always work. Examples includestd::format!(seen above) andtokio::main!. For more info, see Known issues. ↩ ↩2 ↩3
Workspace layout
As mentioned in Name resolution, the preprocessor must know where your crate's entrypoint is.
To do that, it tries to find a Cargo.toml by running
cargo locate-project, by default from the current working directory.
If you have a single-crate setup, this should "just work", regardless of where your book directory is within your source tree.
If you are using Cargo workspaces, then the preprocessor may fail with the message:
Error: Cargo.toml does not have any lib or bin target
This means it found your workspace Cargo.toml instead of a member crate's. To use the
preprocessor in this case, some extra setup is needed.
Sections
Using the manifest-dir option
In your book.toml, in the [preprocessor.rustdoc-link] table, set the
manifest-dir option to the relative path to a member
crate.
For example, if you have the following workspace layout:
my-workspace/
├── crates/
│ └── fancy-crate/
│ ├── src/
│ │ └── lib.rs
│ └── Cargo.toml
└── docs/
├── src/
│ └── SUMMARY.md
└── book.toml
Then in your book.toml:
[preprocessor.rustdoc-link]
manifest-dir = "../crates/fancy-crate"
important
manifest-dir should be a path relative to book.toml, not relative to workspace
root.
Placing your book inside a member crate
If you have a "main" crate, you can also move your book directory to that crate, and run
mdbook from there:
my-workspace/
└── crates/
├── fancy-crate/
│ ├── docs/
│ │ ├── src/
│ │ │ └── SUMMARY.md
│ │ └── book.toml
│ ├── src/
│ │ └── lib.rs
│ └── Cargo.toml
└── util-crate/
└── ...
Documenting multiple crates
If you would like to document items from several independent crates, but still would like to centralize your book in one place — unfortunately, the preprocessor does not yet have the ability to work with multiple entrypoints.
A possible workaround would be to turn your book folder into a private crate that depends on the crates you would like to document. Then you can link to them as if they were third-party crates.
my-workspace/
├── crates/
│ ├── fancy-crate/
│ │ └── Cargo.toml
│ └── awesome-crate/
│ └── Cargo.toml
├── docs/
│ ├── Cargo.toml
│ └── book.toml
└── Cargo.toml
# docs/Cargo.toml
[dependencies]
fancy-crate = { path = "../crates/fancy-crate" }
awesome-crate = { path = "../crates/awesome-crate" }
# Cargo.toml
[workspace]
members = ["crates/*", "docs"]
default-members = ["crates/*"]
resolver = "2"
Using without a Cargo project
If your book isn't for a Rust project, but you still find a use in this preprocessor
(e.g. perhaps you would like to mention std) — unfortunately, the preprocessor does
not yet support running without a Cargo project.
Instead, you can setup your book project as a private, dummy crate.
my-book/
├── src/
│ └── SUMMARY.md
├── book.toml
└── Cargo.toml
# Cargo.toml
[dependencies]
# empty, or you can add anything you need to document
Caching
By default, mdbook-rustdoc-link spawns a fresh rust-analyzer process every time it
is run. rust-analyzer then reindexes your entire project before resolving links.
This significantly impacts the responsiveness of mdbook serve — it is as if for every
live reload, you had to reopen your editor, and it gets even worse the more dependencies
your project has.
To mitigate this, there is an experimental caching feature, disabled by default.
Sections
Enabling caching
In your book.toml, in the [preprocessor.rustdoc-link] table, set
cache-dir to the relative path of a directory of your
choice (other than your book's build-dir), for example:
[preprocessor.rustdoc-link]
cache-dir = "cache"
# You could also point to an arbitrary directory in target/
Now, when mdbook rebuilds your book during build or serve, the preprocessor reuses
the previous resolution and skips rust-analyzer entirely if your edit does not
involve changes in the set of Rust items to be linked, that is, no new items unseen in
the previous build.
important
If you use a directory under your book root directory, make sure to also have a
.gitignore in your book root dir to exclude it from source control, or the cache
file could trigger additional reloads. See Specify exclude
patterns in the mdBook documentation.
Do not use your book's build-dir as the cache-dir: mdbook clears the output
directory on every build, making this setup useless.
How it works
note
The following are implementation details. See rustdoc_link/cache.rs.
The effectiveness of this mechanism is based on the following assumptions:
- Most of the changes made during authoring don't actually involve item links.
- Assuming the environment is unchanged, the same set of items should resolve to the same set of links.
The cache keeps the following information in a cache.json:
- The set of items to be resolved, and their resolved links
- The environment, as a checksum over the contents of:
- Your crate's
Cargo.toml - If you are using a workspace, the workspace's
Cargo.toml - The entrypoint (
lib.rsormain.rs) - For each item that is defined within your crate or workspace, its source file
- (Note that
Cargo.lockis currently not considered, nor are dependencies orstd)
- Your crate's
If a subsequent run has the same set of items (or a subset) and the same checksum (meaning you did not update your code), then the preprocessor simply reuses the previous results.
tip
Items that fail to resolve are not included in the cache.
If you keep such broken links in your Markdown source, the cache will permanently miss, and rust-analyzer will run on every edit.
Help wanted 🙌
The cache feature, as it currently stands, is a workaround at best. If you have insights on how performance could be further improved, please open an issue!
Cache priming and progress tracking
The preprocessor spawns rust-analyzer with cache priming enabled which contributes to the majority of build time.
Furthermore, the preprocessor relies on the LSP Work Done Progress notifications to know when rust-analyzer has finished cache priming, before actually sending out external docs requests. This requires parsing non-structured log messages that rust-analyzer sends out and some debouncing/throttling logic, which is not ideal, see client.rs.
Not waiting for indexing to finish and sending out requests too early causes rust-analyzer to respond with empty results.
Questions:
- Is it possible to do it without cache priming?
- Is there a better way to track rust-analyzer's "readiness" without having to arbitrary sleep?
Using ra-multiplex
ra-multiplex "allows multiple LSP clients (editor windows) to share a single
rust-analyzer instance per cargo workspace."
In theory, in an IDE setting (e.g. with VS Code), one could setup the IDE and
mdbook-rustdoc-link to both connect to the same ra-multiplex server. Then the
preprocessor doesn't need to wait for cache priming (the cache is already warm from IDE
use). Changes in the workspace could also be reflected in subsequent builds without the
preprocessor being aware of them (because the IDE is doing the synchronizing).
In reality, with the current version, connecting the preprocessor to ra-multiplex
seems to result in buggy builds. The initial build emits in many warnings despite all
items eventually resolving. Subsequent builds hang indefinitely before timing out.
Question:
- Is it possible to use
ra-multiplexhere?
Postscript
mdbook encourages a stateless architecture for preprocessors. Preprocessors are
expected to work like pure functions over the entire book, even for mdbook serve.
Preprocessors are not informed on whether they are invoked as part of mdbook build
(prefer fresh starts) or mdbook serve (maintain states between run).
rust-analyzer, meanwhile, has a stateful architecture that also doesn't yet have
persistent caching1. It is designed to take
in a ground state (your project initially) and then evolve the state (your project
edited) entirely in memory.
So rust-analyzer has an extremely incremental architecture, perfect for complex
languages like Rust, and mdbook has an explicitly non-incremental architecture,
perfect for rendering Markdown. This makes them somewhat challenging to work well
together in a live-reload scenario.
-
It was mentioned that the recently updated, salsa-ified rust-analyzer (version
2025-03-17) will unblock work on persistent caching, among many other things, so hopefully bigger changes are coming! ↩
Standalone usage
You can use mdbook-rustdoc-link as a standalone Markdown processor from the command
line.
Simply use the markdown subcommand, send your Markdown through stdin, and receive the
result through stdout, for example:
mdbook-rustdoc-link markdown < README.md
The command accepts as arguments all options configurable in
book.toml, such as --cache-dir. Run
mdbook-rustdoc-link markdown --help to see them.
Continuous integration
This page gives information and tips for using mdbook-rustdoc-link in a continuous
integration (CI) environment.
The preprocessor behaves differently in terms of logging, error handling, etc., when it detects it is running in CI.
Detecting CI
To determine whether it is running in CI, the preprocessor honors the CI environment
variable. Specifically:
- If
CIis set to"true", then it is considered in CI1; - Otherwise, it is considered not in CI.
Most major CI/CD services, such as GitHub Actions and GitLab CI/CD, automatically configure this variable for you.
Installing rust-analyzer
rust-analyzer must be on PATH when running in CI2.
One way is to install it via rustup. For example, in GitHub Actions, you can use:
steps:
- uses: dtolnay/rust-toolchain@stable
with:
components: rust-analyzer
note
Be aware that rust-analyzer from rustup follows Rust's release schedule, which means it may lag behind the version bundled with the VS Code extension.
Logging
By default, the preprocessor shows a progress spinner when it is running.
When running in CI, progress is instead printed as logs (using log and env_logger)3.
You can control logging levels using the RUST_LOG environment variable.
Error handling
By default, when the preprocessor encounters any non-fatal issues, such as when a link
fails to resolve, it prints them as warnings but continues to run. This is so that your
book continues to build via mdbook serve while you make edits.
When running in CI, all such warnings are promoted to errors. The preprocessor will exit with a non-zero status code when there are warnings, which will fail your build. This prevents outdated or incorrect links from being accidentally deployed.
You can explicitly control this behavior using the
fail-on-warnings option.
-
Specifically, when
CIis anything other than"","0", or"false". The logic is encapsulated in theis_cifunction. ↩ -
Unless you use the
rust-analyzeroption. ↩ -
Specifically, when stderr is redirected to something that isn't a terminal, such as a file. ↩
Configuration
This page lists all options for the preprocessor.
For use in book.toml, configure under the [preprocessor.rustdoc-link] table using
the keys below, for example:
[preprocessor.rustdoc-link]
rust-analyzer = "path/to/rust-analyzer --option ..."
For use on the command line, use the keys as long arguments, for example:
mdbook-rustdoc-link markdown --rust-analyzer "..."
| Option | Summary |
|
Directory in which to persist build cache |
|
|
List of features to activate when running rust-analyzer |
|
|
Exit with a non-zero status code when some links fail to resolve |
|
|
Directory from which to search for a Cargo project |
|
|
Command to use for spawning rust-analyzer |
|
|
Timeout in seconds to wait for rust-analyzer to finish indexing |
|
|
Whether to enable punctuations like smart quotes |
cache-dir
Directory in which to persist build cache.
Setting this will enable caching. Will skip rust-analyzer if cache hits.
| Default |
|
|---|---|
| Type |
cargo-features
List of features to activate when running rust-analyzer.
This is just the rust-analyzer.cargo.features config.
In book.toml — to enable all features, use ["all"].
For CLI — to enable multiple features, specify as comma-separated values, or specify multiple times; to enable all features, specify --cargo-features all.
| Default |
|
|---|---|
| Type |
fail-on-warnings
Exit with a non-zero status code when some links fail to resolve.
Warnings are always printed to the console regardless of this option.
| Choice | Description |
"ci"
|
Fail if the environment variable |
"always"
|
Fail as long as there are warnings, even in local use |
| Default |
|
|---|---|
| Type |
manifest-dir
Directory from which to search for a Cargo project.
By default, the current working directory is used. Use this option to specify a different directory.
The processor requires the Cargo.toml of a package to work. If you are working on a Cargo workspace, set this to the relative path to a member crate.
| Default |
|
|---|---|
| Type |
rust-analyzer
Command to use for spawning rust-analyzer.
By default, prebuilt binary from the VS Code extension is tried. If that doesn't exist, it is assumed that rust-analyzer is on PATH. Use this option to override this behavior completely.
The command string will be tokenized by shlex, so you can include arguments in it.
| Default |
|
|---|---|
| Type |
rust-analyzer-timeout
| Default |
|
|---|---|
| Type |
smart-punctuation
Whether to enable punctuations like smart quotes “”.
This is only meaningful if your links happen to have visible text that has specific punctuation. The processor otherwise passes through the rest of your Markdown source untouched.
In book.toml — this option is not needed because output.html.smart-punctuation is honored.
| Default |
|
|---|---|
| Type |
Known issues
Sections
Performance
mdbook-rustdoc-link itself doesn't need much processing power, but it invokes
rust-analyzer, which does a full scan of your workspace. The larger your codebase is,
the longer mdbook will have to wait for the preprocessor. This is the source of the
majority of the run time.
There is an experimental caching feature, which persists query results after runs and reuses them when possible, avoiding spawning rust-analyzer when your edit doesn't involve item links.
Incorrect links
In limited circumstances, the preprocessor generates links that are incorrect or inaccessible.
note
The following observations are based on rust-analyzer
2025-03-17.
Macros
Macros exported with #[macro_export] are always exported at crate
root, and are documented as such by rustdoc, but rust-analyzer currently generates links
to the modules they are defined in. For example:
panic!stdmacros- The correct link is
https://doc.rust-lang.org/stable/std
/macros/macro.panic.html
- The correct link is
https://doc.rust-lang.org/stable/std
serde_json::json!- The correct link is
https://docs.rs/serde_json/1.0.140/serde_json
/macros/macro.json.html
- The correct link is
https://docs.rs/serde_json/1.0.140/serde_json
Attribute macros generate links that use macro.<macro_name>.html, but rustdoc actually
generates attr.<macro_name>.html. For example:
tokio::main!- The correct link is
https://docs.rs/tokio-macros/2.5.0/tokio_macros/
macroattr.main.html
- The correct link is
https://docs.rs/tokio-macros/2.5.0/tokio_macros/
Trait items
Rust allows methods to have the same name if they are from different traits, and types can implement the same trait multiple times if the trait is generic. All such methods will appear on the same page for the type.
rustdoc will number the generated URL fragments so that they remain unique within the HTML document. rust-analyzer does not yet have the ability to do so.
For example, these are the same links:
<std::net::IpAddr as From<std::net::Ipv4Addr>>::from<std::net::IpAddr as From<std::net::Ipv6Addr>>::from
The correct link for the From<Ipv6Addr> implementation is actually
https://doc.rust-lang.org/stable/core/net/enum.IpAddr.html#method.from-1
Private items
rustdoc has a private_intra_doc_links lint that warns you
when your public documentation tries to link to private items.
The preprocessor does not yet warn you about links to private items: rust-analyzer will generate links for items regardless of their crate-level visibility.
Unresolved items
Associated items on primitive types
note
The following observations are based on rust-analyzer
2025-03-17.
Links to associated methods and items on primitive types are currently not resolved by rust-analyzer. For example:
- [
str::parse] - [
f64::MIN_POSITIVE]
Sites other than docs.rs
Currently, items from crates other than std always generate links that point to
https://docs.rs. mdbook-rustdoc-link does not yet support configuring alternative
hosting sites for crates (such as wasm-bindgen which hosts API docs under
https://rustwasm.github.io/wasm-bindgen/api/).
Wrong line numbers in diagnostics
When the preprocessor fails to resolve some items, it emits warnings that look like:

You may notice that the line numbers are sometimes incorrect for your source file. This
could happen in files that use the {{#include}} directive, for example.
This is an unfortunate limitation with mdBook's preprocessor architecture. Preprocessors
are run sequentially, with the next preprocessor receiving Markdown source rendered by
the previous one. If preprocessors running before mdbook-rustdoc-link modify Markdown
source in such ways that shift lines around, then the line numbers will look incorrect.
Unless mdBook somehow gains source map support, this problem is unlikely to ever be solved.
mdbook-link-forever
mdBook preprocessor that takes care of linking to files in your Git repository.
mdbook-link-forever rewrites path-based links to version-pinned GitHub permalinks. No
more hard-coded GitHub URLs.
Here's a link to the [Cargo workspace manifest](../../../Cargo.toml).
Here's a link to the Cargo workspace manifest.
- Versions are determined at build time. Supports both tags and commit hashes.
- Because paths are readily accessible at build time, it also validates them for you.
Getting started
-
Install this crate:
cargo install mdbookkit --features link-forever -
Configure your
book.toml:[book] title = "My Book" [output.html] git-repository-url = "https://github.com/me/my-awesome-crate" # will use this for permalinks [preprocessor.link-forever] # mdBook will run `mdbook-link-forever` -
Link to files using paths, like this:
See [`book.toml`](../../book.toml#L44-L48) for an example config.See
book.tomlfor an example config.
License
This project is released under the Apache 2.0 License and the MIT License.
Features
Permalinks
Simply use relative paths to link to any file in your source tree, and the preprocessor will convert them to GitHub permalinks.
This project is dual licensed under the [Apache License, Version 2.0](../../../LICENSE-APACHE.md) and the [MIT (Expat) License](../../../LICENSE-MIT.md).This project is dual licensed under the Apache License, Version 2.0 and the MIT (Expat) License.
Permalinks use the tag name or commit SHA of HEAD at build time, so you get a rendered book with intra-repo links that are always correct for that point in time.
tip
Linking by path is cool! Not only is it well-supported by GitHub, but editors like VS Code also provide smart features like path completions and link validation.
URL fragments are preserved:
This book uses [esbuild] to [preprocess its style sheet](../../app/build/build.ts#L13-L24).This book uses esbuild to preprocess its style sheet.
By default, links to files under your book's src/ directory are not converted, since
mdBook already copies them to build output, but this is configurable
using the always-link option.
Repo auto-discovery
To know what GitHub repository to link to, the preprocessor looks at the following places, in order:
- The
output.html.git-repository-urloption in yourbook.toml - The URL of a Git remote named
origin1
tip
For Git remotes, both HTTP URLs and "scp-like" URIs (git@github.com:org/repo.git)
are supported, thanks to the gix_url crate.
If you use Git but not GitHub, you can configure a custom URL pattern using the
repo-url-template option. For example:
[preprocessor.link-forever]
repo-url-template = "https://gitlab.haskell.org/ghc/ghc/-/tree/{ref}/{path}"
Link validation
The preprocessor validates any path-based links and notifies you if they are broken.
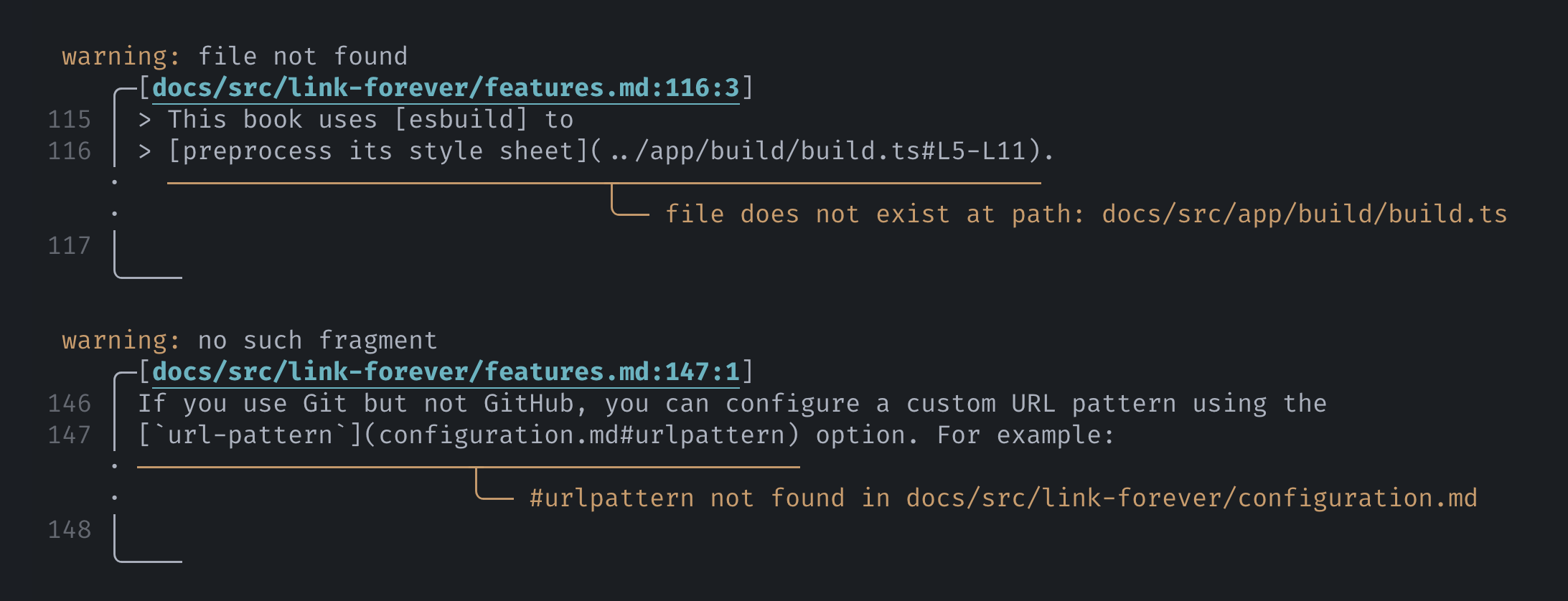
Formatting of diagnostics powered by miette
note
Link validations are only supported for path-based links. For more comprehensive link
checking, look to projects like mdbook-linkcheck.
-
The remote must be exactly named
origin. No other name is recognized. ↩
Working with {{#include}}
mdBook provides an {{#include}} directive for embedding files in
book pages. If the embedded content also contains path-based links, then some extra care
may be needed:
-
The preprocessor does not resolve links relative to the file being included (because it doesn't have enough information to do so). In this case, relative paths could be valid for the source file (and therefore valid for e.g. GitHub) but invalid for the book.
-
In some situations, you cannot use path-based links and you have to use full URLs. This could be because the included file is also intended for platforms that don't support paths as links.
This page describes some workarounds for linking in included files.
Using absolute paths
To use paths as links in included content, you can use absolute paths that start with a
/. Paths that start with a / are resolved relative to the root of your repository:
Front page of this book is actually from [the crate README](/crates/mdbookkit/README.md).Front page of this book is actually from the crate README.
Extra feature: Using URLs to link to book pages
You may be in a situation where you have to use full URLs to link to your book rather than relying on paths.
An example (that this project encountered) is including files that are also intended for displaying on crates.io.
In this case, since other platforms like crates.io will not convert path-based
.mdlinks to URLs, linking to book pages would require writing down full URLs to the deployed book.
To mitigate this, you can use the book-url option.
In your book.toml, in the [preprocessor.link-forever] table, specify the URL prefix
at which you will deploy your book:
[preprocessor.link-forever]
book-url = "https://example.org/"
Then, in Markdown, you may use full URLs, for example:
For a list of the crate's features, see [Feature flags](https://example.org/features).For a list of the crate's features, see Feature flags.
Specifying book-url enables the preprocessor to check URLs to your book against local
paths. If a URL does not have a corresponding .md file under your book's src/
directory, the preprocessor will warn you:

note
book-url only enables validation, and is only for links to your book, not to GitHub.
Continuous integration
This page gives information and tips for using mdbook-link-forever in a continuous
integration (CI) environment.
The preprocessor behaves differently in terms of logging, error handling, etc., when it detects it is running in CI.
Detecting CI
To determine whether it is running in CI, the preprocessor honors the CI environment
variable. Specifically:
- If
CIis set to"true", then it is considered in CI1; - Otherwise, it is considered not in CI.
Most major CI/CD services, such as GitHub Actions and GitLab CI/CD, automatically configure this variable for you.
Linking to Git tags
The preprocessor supports both tags and commit SHAs when generating permalinks. The use of tags is contingent on HEAD being tagged in local Git at build time. You should ensure that tags are present when building in CI, or the preprocessor will fallback to using the full SHA (it would still be a permalink, just that it will be more verbose).
For example, in GitHub Actions, you can use:
steps:
- uses: actions/checkout@v4
with:
fetch-tags: true
fetch-depth: 0 # https://github.com/actions/checkout/issues/1471#issuecomment-1771231294
Logging
By default, the preprocessor shows a progress spinner when it is running.
When running in CI, progress is instead printed as logs (using log and env_logger)2.
You can control logging levels using the RUST_LOG environment variable.
Error handling
By default, when the preprocessor encounters any non-fatal issues, such as when a link
fails to resolve, it prints them as warnings but continues to run. This is so that your
book continues to build via mdbook serve while you make edits.
When running in CI, all such warnings are promoted to errors. The preprocessor will exit with a non-zero status code when there are warnings, which will fail your build. This prevents outdated or incorrect links from being accidentally deployed.
You can explicitly control this behavior using the
fail-on-warnings option.
-
Specifically, when
CIis anything other than"","0", or"false". The logic is encapsulated in theis_cifunction. ↩ -
Specifically, when stderr is redirected to something that isn't a terminal, such as a file. ↩
Configuration
This page lists all options for the preprocessor.
For use in book.toml, configure under the [preprocessor.link-forever] table using
the keys below, for example:
[preprocessor.link-forever]
always-link = [".rs"]
| Option | Summary |
|
Convert some paths to permalinks even if they are under |
|
|
Specify the canonical URL at which you deploy your book. |
|
|
Exit with a non-zero status code when there are warnings |
|
|
Use a custom link format for platforms other than GitHub. |
always-link
Convert some paths to permalinks even if they are under src/.
By default, links to files in your book's src/ directory will not be transformed,
since they are already copied to build output as static files. If you want such files
to always be rendered as permalinks, specify their file extensions here.
For example, to use permalinks for Rust source files even if they are in the book's
src/ directory:
always-link = [".rs"]
| Default |
|
|---|---|
| Type |
book-url
Specify the canonical URL at which you deploy your book.
Should be a qualified URL. For example:
book-url = "https://me.github.io/my-awesome-crate/"
Enables validation of hard-coded links to book pages. The preprocessor will warn you about links that are no longer valid (file not found) at build time.
This is mainly used with mdBook's {{#include}} feature, where sometimes you
have to specify full URLs because path-based links are not supported.
| Default |
|
|---|---|
| Type |
fail-on-warnings
Exit with a non-zero status code when there are warnings.
Warnings are always printed to the console regardless of this option.
| Choice | Description |
"ci"
|
Fail if the environment variable |
"always"
|
Fail as long as there are warnings, even in local use |
| Default |
|
|---|---|
| Type |
repo-url-template
Use a custom link format for platforms other than GitHub.
Should be a string that contains the following placeholders that will be filled in at build time:
{ref}— the Git reference (tag or commit ID) resolved at build time{path}— path to the linked file relative to repo root, without a leading/
For example, the following configures generated links to use GitLab's format:
repo-url-template = "https://gitlab.haskell.org/ghc/ghc/-/tree/{ref}/{path}"
Note that information such as repo owner or name will not be filled in. If URLs to your Git hosting service require such items, you should hard-code them in the pattern.
| Default |
|
|---|---|
| Type |
Known issues
Working with {{#include}}
Linking by relative paths may not make sense when the links are in files that are
embedded using mdBook's {{#include}} directive.
See Working with {{#include}} for some possible
workarounds.
Links in HTML
Links in HTML (href and src) are currently neither transformed nor checked.
CHANGELOG
The format is based on Keep a Changelog.
This file is autogenerated using release-plz.
1.1.2
rustdoc-link
Bug fixes
Refactor
- print RA version on bail
0746536
1.1.1
link-forever
Bug fixes
1.1.0
link-forever
Features
CHANGELOG
The format is based on Keep a Changelog.
This file is autogenerated using release-plz
1.0.1 - 2025-04-08
Other
1.0.0 - 2025-04-08
Initial release.
INTERNAL: Repo README
note
This page is included only for link validation during build.

mdbookkit
Quality-of-life plugins for your mdBook project.
Read the book
You may be looking for: